
DeepMind, de Artificial Intelligence investering van Google, leert kunstmatige intelligentie om jaren ’80 Atari spelletjes te spelen zonder instructies. En ze zijn goed. Heel erg goed. Space Invaders, BreakOut en Video Pinball worden als instrument gebruikt om de systemen binnen een afgeschermde en beperkte omgeving te leren werken en scoren.
Ai systemen leren zonder instructie
De enige instructie die ze aan de zelflerende software geven is te proberen een zo hoog mogelijke score te behalen binnen een zo kort mogelijke tijd. Dan begint de software zonder enig beeld van het spel en het doel om gewoon te spelen. Gaandeweg leert het welk gedrag de score laat oplopen en welk gedrag Game Over geeft. Zo kan het duizenden spelletjes per dag spelen en ieder keer een heel klein beetje beter worden. Maar het gaat snel. Binnen een paar dagen continue spelen krijg je dit:
Het is bijna (of helemaal, nou ja helemaal) afschuwelijk om de efficiency van de Ai te zien. Er is geen move teveel en alles is raak.
Hoger doel
Maar er is een hoger doel. Vanuit Atari spelletjes legt DeepMind de basis voor systemen die ook in de echt wereld kunnen functioneren. Ook daar geldt trial en error, leren en verbeteren. Dat is natuurlijk ook de reden dat ze deze route lopen. Eerst een ‘kaart’ maken van de wereld en vervolgens leren wat je er kan doen. De algoritmes van DeepMind gebruiken een soort beloningssysteem voor de Ai om hem te laten zien dat een bepaalde volgorde van handelingen gewenst was. Een hogere score leidt tot een soort virtuele dopamine waarmee het systeem getriggerd wordt het goede gedrag te herhalen.
Ze noemen het systeem Osara. Dat staat voor Obervation, State inference, Action, Reward. En als het goed is gaat de cirkel weer terug naar Observation.
Related Posts
Wij mensen denken natuurlijk dat we met onze ogen heel veel kunnen zien. Dat klopt eigenlijk niet. Er is vooral heel veel dat we niet kunnen zien. Samen met Paul Voerman, Head of Innovations bij Tricas, leg ik in onderstaand artikel uit waar we staan en hoe robots ons met hun fantastische ogen kunnen helpen.
We behandelen eerst de technische kant en gaan dan een paar voorbeelden geven van het nut van robot ogen.
Resolutie
Robots kunnen met een veel hogere resolutie kijken dan wij. Uit je oog komen twee miljoen zenuwen die het beeld dat op je netvlies valt, doorgeven aan je hersenen. Als je zenuwen met pixels vergelijkt, heeft het oog dus twee miljoen pixels. Een goede camera op een telefoon heeft met 20 miljoen pixels dus al het tienvoudige. Maar dat is nog maar het begin, want als je een robot zou gebruiken dan kan dit nog veel verder omhoog. Exponentieel je weet wel.
Contrast
Ons computer kleurenspectrum is meestal opgedeeld in 16.5 miljoen kleuren. Met moeite kunnen we als mensen 5 punten verschil zien. Dat is al knap maar een robot kan veel kleinere verschillen onderscheiden. De kleurverschillen tussen de bolletjes hieronder zijn lastig te zien voor ons maar geen enkel probleem voor een robotoog.

Een robot oog laat zich niet verleiden door de eigen interpretatie van de hersenen, dat doen mensen continu en dat verkleint bij ons de objectieve werkelijkheid helaas.
Snelheid
De snelheid van het menselijk oog in beelden per seconde meten is technisch niet te doen. Het gaat namelijk om of je iets ziet (draaiend wiel) en hoe goed (elke spaak van het wiel). Dat een camera het in iedere geval veel beter kan behoeft geen betoog eigenlijk. Om mooie slow motion opnames te maken is een framerate van 960 al vrij gebruikelijk. Dit verbleekt bij de 100.000 frames per seconde van gespecialiseerde camera’s voor super slow motion.
Een stukje in het elektromagnetisch spectrum
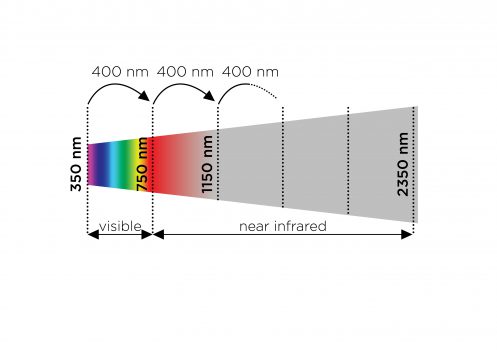
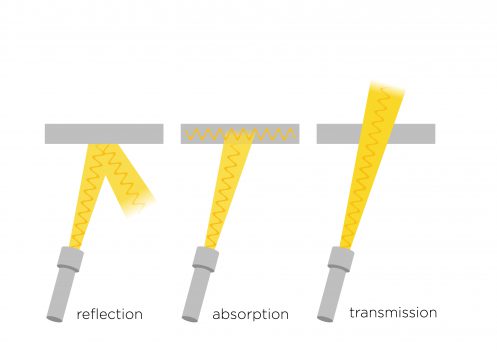
Op het spectrum van near-infrared staan onze ogen buitenspel. Kijk eens hierboven in het plaatje, dan zie je hoeveel we (onze ogen) eigenlijk missen! Het licht gedraagt zich in dit gedeelte van het spectrum namelijk niet anders dan in het voor ons zichtbare spectrum. Ook hier is het spel van reflectie, absorptie en doorlatend. Eigenschappen die voor ons niet zichtbaar zijn worden met near-infrared wel zichtbaar.
Toepassingen
We kunnen gelukkig robots en andere machines uitrusten met camera’s die erg goed, snel en scherp kunnen kunnen kijken. Wat zouden ze dan kunnen zien waar wij wat aan hebben? Hieronder een topje van de ijsberg. Er zijn namelijk duizenden toepassingen te verzinnen.
- Ongewenste vervuiling / schimmels op onze voeding. Dat lijkt me super! Je robot wijst in de winkel op het meest verse eten. Veel minder kans op voedselvergiftiging. Dat kleine puntje dat jij niet ziet is helder aanwezig met near-infrared. Maar ook de kleur van voedsel bevat veel meer informatie voor de robot dan voor ons.
- Onregelmatigheden op de huid van mens en dier. Ook deze kan een robot zien en wij niet. Denk aan huidkanker, meteen spotten is hogere overlevingskans! Iedere spiegel met een goede camera erin zou jou en je gezin dagelijks zonder gedoe kunnen checken.
- De gezondheid van gewassen. Vanuit een drone kan snel worden bekeken welke gewassen gezond of ziek zijn. Maar de drone ziet ook exact welke gewassen er staan via near-infrared.

- Verschillende kunststoffen die er voor ons hetzelfde uitzien. Als je bij de recycling van kunststoffen op mensen vertrouwt dan gooi je allerhande soorten bij elkaar. Dat is zeer ongewenst in een circulaire economie.
Bovenstaande voorbeelden zijn puur ter illustratie en om je te prikkelen zelf na te denken over de mogelijkheden.
Ik wil Randall boeken Bekijk Randall op Linkedin
Randall is een ‘disruptive technology strategist’ voor uw keynotes en specifieke workshops. Tevens is Randall te boeken als dagvoorzitter voor innovatiedagen en congressen.
Vorige week was een mooie week met voor mij als hoogtepunt het interview met Prof. dr. ir. Maarten Steinbuch, High Tech Systems Expert. Het gesprek dat ik met hem voerde ging met name over (de misverstanden rond) elektrisch vervoer, de energietransitie en hoe belangrijk je eigen principes zijn in de wetenschap. Hieronder mijn weergave van het gesprek.
We zitten echt weer in zo’n periode van slecht nieuws. Oorlogen, een beurscrash, een pandemie en inflatie.
Het is tijd voor wat goed nieuws. En hier komt het goede nieuws. Met de huidige technologie kunnen we het klimaatprobleem oplossen.
De energie transitie is binnen handbereik
Dat is een simpel en duidelijk statement dat ik een beetje ga uitleggen. Veel mensen denken dat er nog grote technologische stappen moeten worden gezet op het gebied van zonnepanelen, accu’s en waterstof. Dat is niet het geval.
Wat er wel nodig is is een ongelofelijke capaciteitsuitbreiding. Om de hele wereld over te brengen naar duurzame energie is er met name veel opslagcapaciteit nodig. Deze capaciteit zal met name komen uit accu’s ofwel batterijen. Nogmaals, deze batterijen zijn er al maar we hebben er extreem veel nodig. Ik wil het hier niet altijd technisch maken maar ga ervan uit dat we minstens jaarlijks 100 keer zoveel batterijen moeten maken als nu. Dat legt met name eisen op de supply chain en de productiecapaciteit.
Inderdaad je hoort me niet over de grondstoffen praten. de meeste metalen die we nodig hebben voor deze batterijen zijn ruim voorradig. Nikkel en kobalt waar je vaak over leest zijn alleen in uitzonderingsgevallen nodig. De materialen die we nodig hebben zoals lithium en ijzer zijn geen enkel probleem qua voorradigheid. Er moet wel sterk geïnvesteerd worden in nieuwe mijnen en refineries. En vervolgens natuurlijk in accu fabrieken. Het tempo waarin het grote geld deze kant op stroomt maakt mij hoopvol.
We kunnen het: er is heel veel geld mee te verdienen en het maakt de wereld mooier. Een optimist zoals ik zal zelfs zeggen dat het probleem feitelijk is opgelost.
Ik wil Randall boeken Bekijk Randall op Linkedin